
Introduction
AlphaZero is the state-of-art general artificial intelligence designed to play any of the games. My learning notes of AlphaZero, as well as the interpretation of the technical details in depth, are presented in this article. We will not discuss too much about why the algorithm works (actually it is alchemy), but we will learn in detail what they exactly did to make AlphaZero. This article is also self-contained, the readers do not have to learn AlphaGo before learning AlphaZero.
The algorithm of AlphaZero is essentially the same as that of AlphaGo Zero. We are looking at the AlphaGo Zero Nature paper to see how actually AlphaZero works.
AlphaGo Zero
Understanding why AlphaGo Zero works extremely well might not be impossible (given it is alchemy), but learning and even reproducing what they did is not that hard.
AlphaGo Zero was trained as it played against itself. The workflow of AlphaGo Zero is shown below.
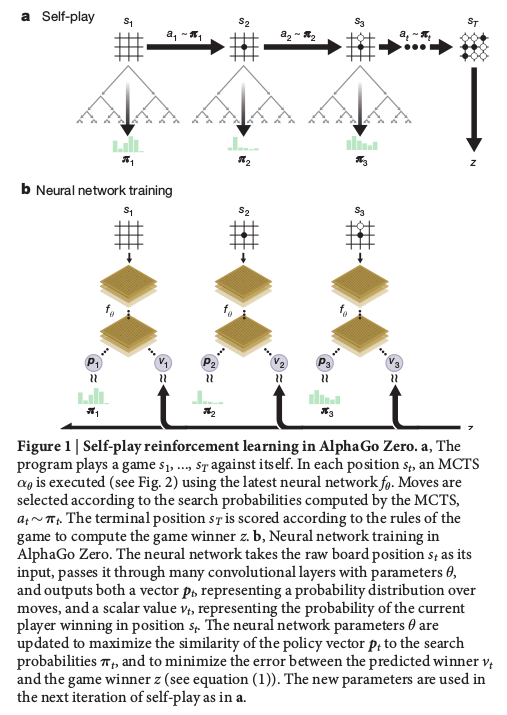
Unlike AlphaGo, the major component of AlphaGo Zero is a single neural network which takes the board representation (position coordinates) $s$ as input and ouputs a move probabilities vector $\boldsymbol{p}$ for valid movements and a winning value $v$ ($0 \leq v \leq 1$) estimating the probability of the current player winning from position state $s$. $(\boldsymbol{p}, v) = f_{\theta}(s_L)$. The probability of taking valid action $a$ could be found in the $\boldsymbol{p}$ vector, $p_a = \text{Pr}(a|s) = \boldsymbol{p}[a]$.
The the neural network was initialized to random weights $\theta_0$. In round $i$ of the game ($i \geq 1$), AlphaGo Zero played against itself. In each time step $t$ of the game, AlphaGo Zero plays one move according to the neural network aided Monte Carlo Tree Search (MCTS) ($a_t \sim \boldsymbol{\pi_t}$). The recommending moves $\boldsymbol{\pi_t}$ is calculated using the neural network parameters in game round $i-1$ and the position state at time step $t$, $\boldsymbol{\pi_t} = \alpha_{\theta_{i-1}}(s_t)$. Don’t worry if you don’t know MCTS. We will elaborate in detail how MCTS works in AlphaGo Zero in the next section. AlphaGo Zero played black stone and white stone alternatedly until the game ends.
There are several scenarios that the game ends:
- The MCTS search value drops below a resignation threshold.
- The game exceeds a maximum length.
The game is then scored to give a final reward of $r_T \in \{−1,+1\}$. Obviously, the winner color gets +1 and the loser color gets -1. But the author did not make it clear how it is scored when The game exceeds a maximum length.
The data for each time-step $t$ is stored as $(s_t , \pi_t , z_t)$, where $z_t = \pm r_T$ is the game winner from the perspective of the current player at step $t$.
To train the neural network parameters, after one round of game, data $(s_t , \pi_t , z_t)$ were sampled uniformly among all time-steps in the last round of game. The neural network $(\boldsymbol{p}, v) = f_{\theta_i}(s)$ is adjusted to minimize the error between the predicted value $v$ and the self-play winner $z$, and to maximize the similarity of the neural network move probabilities $\boldsymbol{p}$ to the search probabilities $\boldsymbol{\pi}$.
Specifically, they uses a loss function $l$ that sums over the mean-squared error and cross-entropy losses for gradient descent.
where $c$ is a parameter controlling the level of $L2$ weight regularization (to prevent overfitting).
Monte Carlo Tree Search
The Monte Carlo Tree Search (MCTS) used in AlphaGo Zero is different to the ones used in AlphaGo Fan and AlphaGo Lee. Here we are going to focus on the MCTS used in AlphaGo Zero without mentioning too much about the ones used in AlphaGo.
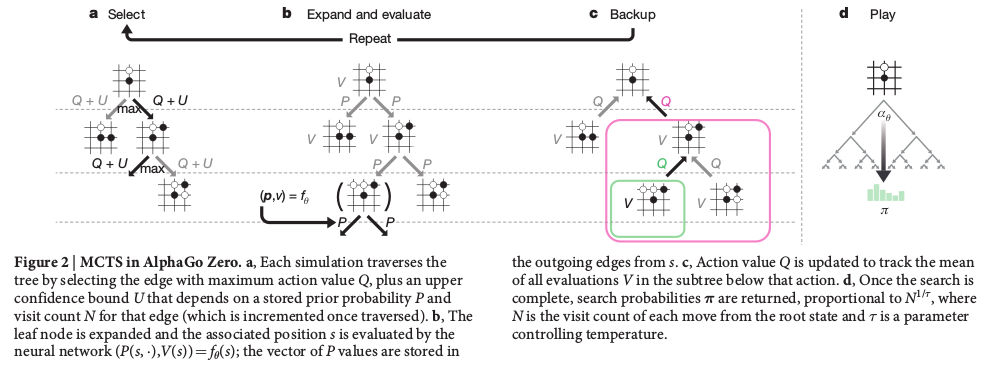
The MCTS figure in the Nature paper presented the workflow of the MCTS in AlphaGo Zero, but it is not very helpful to understand how it works. The implementation details are in the Search algortihm, Select, Expand and evaluate, Backup and Play of the Methods section.
Data Structure
Each node $s$ in the Monte Carlo search tree represents a position state. It has edges $(s,a)$ for all legal actions $a \in A(s)$. Each edge sotres a set of statistics,
where $N(s,a)$ is the visit count, $W(s,a)$ is the total action value, $Q(s,a)$ is the mean action value and $P(s,a)$ is the prior probability of selecting that edge.
We will be clear how there values are obtained as we traverse the tree.
Select
The Monte Carlo tree is generated recursively. Given the current generated tree, the simulation has to traverse the tree by selecting the edge with maximum value of $Q+U$, where $Q$ is the action value and $U$ is the upper confidence bound, until it reaches one of the leaf nodes of the current tree. Do not be confused the leaf nodes with the game end state, they are irrelavent.
For each traverse (root to leaf), we spent time-steps $L$. Each time step we go down on level of the tree until we reach the leaf node. The edges in the traverse path, $(s_0,a_0)$, $(s_1,a_1)$, …, $(s_L,a_L)$, were saved.
During traverse, the next edge connecting the current node $s_t$ was selected by
where $c_{\text{puct}}$ is a constant.
This is analogous to the action choice in traditional Q-Learning.
Expand and Evaluate
After determining the traverse path, the leaf node $s_L$ will be applied to the neural network for evaluation, $(\boldsymbol{p}, v) = f_{\theta}(s_L)$, where $\boldsymbol{p}$ contains the probabilitis for all the valid moves, and $v$ is the probability of winning at position state $s_L$. Each expanded edges $(s_L, a)$ were initialized to $\{N(s,a)=0, W(s,a)=0, Q(s,a)=0, P(s,a)=p_a\}$. The value $v$ from the evaluation will be used in the backup step.
It should be noted that actually they uses a randomly rotated position state of $s_L$ into neural network for evalution, $(d_i(\boldsymbol{p}), v) = f_{\theta}(d_i(s_L)$, where $d_i$ is a dihedral reflection or rotation selected uniformly at random from $i$ in [1…8]. Similar strategy has been used in the AlphaGo Nature paper. My understanding is that because Go is a “symmetric” game, rotating board state should not affect the good move. By doing this the model could probably generalize better. But this might not be applicable to some “non-symmetric” game, such as Chess.
Backup
Update the edge values in the traverse path backward from leaf to root using the winning value $v$ evaluated from neural network.
For all $t \leq L$,
In this way, $Q(s,a)$ is averaging all the winning values during the tree contruction resulting a better estimate of the action value of position state $s$.
MCTS Parallelism
It should also be noted that they introduces a lot of parallelism in the MCTS implementation. For example, they select 8 different children nodes in the search step for the leaf node in parallel. Initially it is impossible to do this because the action chosen for each leaf node is greedy, which means that the 8 different children nodes chosen should be exactly the same one. However, they “use virtual loss to ensure each thread evaluates different nodes”. So each time they traverse the tree in parallel, the 8 traverse paths will never overlap in the tree except for the root node. It sounds fair to do, but I expect the implementation might be very tricky.
Play
After recursively constructing the tree, the actual move for the root position state $s_0$ was chosen by,
After the move, the MCTS was conducted for the next move. The MCT generated in the previous steps could be directly reused. The new position state after the move became the new root. The new root branch will be kept and the rest of the tree will be discarded to save memory.
The AlphaGo Zero also resigns if if its root value and best child value are lower than a threshold value $v_{resign}$. This makes sure that the algorithm did not spend too much time learning how to play in a game where it is almost impossible to win.
Understand the Alchemy
This requires more effort. To be continued.
AlphaZero AIs for Games
Implementing AlphaZero AIs for different games will be fun.