
Introduction
Prefix-free code and Huffman coding are concepts in information theory, but I actually know little in this field. The first time I heard about Huffman coding was actually in the Deep Learning class where the professor was trying to prove the “Source Coding Theorem” using prefix-free codes. Frankly I did not understand too much about the theory, but prefix-free code and Huffman coding turn out to be quite useful in some deep learning tasks, such as a Huffman tree hierarchical softmax [1]. So I need to at least understand the basic concept of prefix-free code and try to construct a huffman tree on my own.
Prefix-Free Code
Prefix-free code and prefix code are actually the same thing (forget about how the namings were done). The formal definition of a prefix-free code system from Wikipedia is as follows:
“A prefix code is a type of code system (typically a variable-length code) distinguished by its possession of the “prefix property”, which requires that there is no whole code word in the system that is a prefix (initial segment) of any other code word in the system. “
Concretely, let us see an example. We have the following one-to-one binary code system, represented using a dictionary.
A: 00
B: 010
C: 011
D: 10
E: 11
We could check the word one by one to see whether the system satisfies the “prefix property”. A was coded as 00, while none of the codes of B, C, D, and E are started with 00. Using the same way, we check B, C, D, and E, and confirm that it is a prefix-free code system.
If we change the above system a little bit to the following system:
A: 00
B: 010
C: 001 # 011 -> 001
D: 10
E: 11
The new system is still one-to-one correspondent. However, it is no-longer prefix-free code system, because the code of A 00 was shown as the prefix in the code of C which is 001.
Prefix-Free Code Tree
We represent the above prefix-free code system as a binary tree.
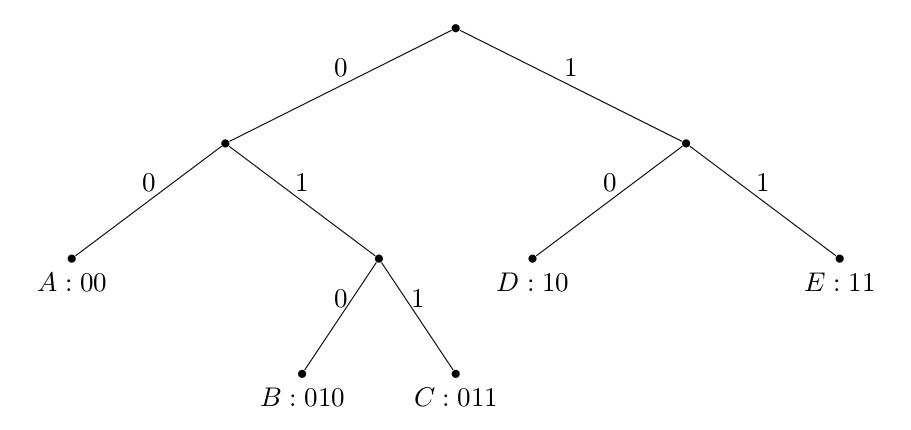
Suppose the probability of choosing the left branch is the same to choosing the right branch, i.e., $P(0) = P(1) = \frac{1}{2}$ for each node, we have: $P(A) = \frac{1}{4}$, $P(B) = \frac{1}{8}$, $P(C) = \frac{1}{8}$, $P(D) = \frac{1}{4}$, $P(E) = \frac{1}{4}$, and $P(A) + P(B) + P(C) + P(D) + P(E) = 1$.
It should be noted that $P(0) = P(1) = \frac{1}{2}$ was used just for illustration purpose, it might not be true in real examples. But even if the branching probabilities are not the same, the sum of all the leaf probabilities should always be exactly 1.
Huffman Tree
Huffman tree is a prefix-free code tree. The specialty of Huffman tree compared to an ordinary prefix-free code tree is that it minimizes the probability weighted mean of code length in the system. Here the “probability” is the probability of word shown in the system. For example, we have a system “AAAAABBBBCCCDDE”, the probabilities of words are $P(A) = \frac{1}{3}$, $P(B) = \frac{4}{15}$, $P(C) = \frac{1}{5}$, $P(D) = \frac{2}{15}$, $P(E) = \frac{1}{15}$.
The $O(n\log n)$ and $O(n)$ algorithms of constructing Huffman tree were described in the Huffman tree Wikipedia.
The Huffman tree of this example constructed is:
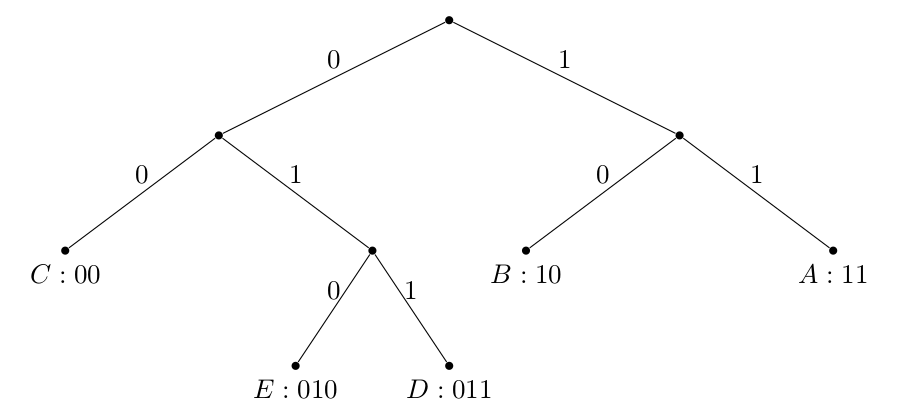
Constructing Huffman Tree
I first wanted to try implementing Huffman coding on my own, but later I found that probably does not worth of spending my time. There are some open-sourced Huffman coding codes on GitHub, and there are two Python libraries of huffman coding, huffman and dahuffman, available.
So let us try to construct the huffman tree for the system “AAAAABBBBCCCDDE” using huffman and dahuffman libraries.
To install huffman or dahuffman:
pip install huffman
pip install dahuffman
Huffman Library
Use huffman library:
import huffman
import collections
huffman.codebook([('A', 5), ('B', 4), ('C', 3), ('D', 2), ('E', 1)])
# Alternatively
# huffman.codebook(collections.Counter("AAAAABBBBCCCDDE").items())
We got the huffman coding:
{'A': '11', 'B': '10', 'C': '00', 'D': '011', 'E': '010'}
Dahuffman Library
Use dahuffman library:
from dahuffman import HuffmanCodec
codec = HuffmanCodec.from_frequencies({'A': 5, 'B': 4, 'C': 3, 'D': 2, 'E': 1})
# Alternatively
# codec = HuffmanCodec.from_data("AAAAABBBBCCCDDE")
codec.print_code_table()
We got the huffman coding:
bits code (value) symbol
4 0100 ( 4) _EOF
2 11 ( 3) 'A'
2 10 ( 2) 'B'
2 00 ( 0) 'C'
3 011 ( 3) 'D'
4 0101 ( 5) 'E'
It seems that _EOF is a default symbol for Huffman coding, I currently have not find out how to get rid of _EOF for Huffman coding. However, huffman library resulted in the same Huffman coding as dahuffman library if I introduce _EOF.
Use huffman library:
import huffman
huffman.codebook([('A', 5), ('B', 4), ('C', 3), ('D', 2), ('E', 1), ('_EOF', 0)])
We got the huffman coding:
{'A': '11', 'B': '10', 'C': '00', 'D': '011', 'E': '0101', 'EOF': '0100'}
Which is exactly the same to the Huffman coding obtained using dahuffman library.
Conclusion
Using huffman or dahuffman library, we could easily construct Huffman tree without knowing too much details about the tree constructing algorithms. For a more realistic example, we are going to do huffman coding for the words in the passage:
Bellman was born in 1920 in New York City to non-practising Jewish parents of Polish and Russian descent, Pearl (née Saffian) and John James Bellman, who ran a small grocery store on Bergen Street near Prospect Park, Brooklyn. He attended Abraham Lincoln High School, Brooklyn in 1937, and studied mathematics at Brooklyn College where he earned a BA in 1941. He later earned an MA from the University of Wisconsin–Madison. During World War II he worked for a Theoretical Physics Division group in Los Alamos. In 1946 he received his Ph.D at Princeton under the supervision of Solomon Lefschetz. Beginning 1949 Bellman worked for many years at RAND corporation and it was during this time that he developed dynamic programming.
Use huffman library:
import huffman
from collections import Counter
passage = "Bellman was born in 1920 in New York City to non-practising Jewish parents of Polish and Russian descent, Pearl (née Saffian) and John James Bellman, who ran a small grocery store on Bergen Street near Prospect Park, Brooklyn. He attended Abraham Lincoln High School, Brooklyn in 1937, and studied mathematics at Brooklyn College where he earned a BA in 1941. He later earned an MA from the University of Wisconsin–Madison. During World War II he worked for a Theoretical Physics Division group in Los Alamos. In 1946 he received his Ph.D at Princeton under the supervision of Solomon Lefschetz. Beginning 1949 Bellman worked for many years at RAND corporation and it was during this time that he developed dynamic programming."
word_count = Counter(passage.split(' '))
word_frequencies = []
for item in word_count.items():
word_frequencies.append(item)
huffman.codebook(word_frequencies)
We got the huffman coding:
{'(née': '1111111',
'1920': '1100010',
'1937,': '0011101',
'1941.': '1001101',
'1946': '1111011',
'1949': '0011001',
'Abraham': '1111110',
'Alamos.': '0101101',
'BA': '0011000',
'Beginning': '1100111',
'Bellman': '100010',
'Bellman,': '1101010',
'Bergen': '1010101',
'Brooklyn': '010010',
'Brooklyn.': '1100101',
'City': '1101100',
'College': '1000111',
'Division': '1011000',
'During': '0110110',
'He': '101110',
'High': '0100000',
'II': '1010111',
'In': '000100',
'James': '0110010',
'Jewish': '1101011',
'John': '1110000',
'Lefschetz.': '0011011',
'Lincoln': '0111110',
'Los': '000101',
'MA': '0011100',
'New': '0111100',
'Park,': '0100110',
'Pearl': '1100000',
'Ph.D': '1111001',
'Physics': '1101001',
'Polish': '1110100',
'Princeton': '1010011',
'Prospect': '1110001',
'RAND': '0101110',
'Russian': '1100110',
'Saffian)': '0011010',
'School,': '1001100',
'Solomon': '0100001',
'Street': '1110110',
'Theoretical': '1011001',
'University': '0111010',
'War': '1010100',
'Wisconsin–Madison.': '0111000',
'World': '1111100',
'York': '1111101',
'a': '00100',
'an': '0011111',
'and': '01010',
'at': '00101',
'attended': '1011010',
'born': '1000110',
'corporation': '0011110',
'descent,': '0100111',
'developed': '1011111',
'during': '1010001',
'dynamic': '1011110',
'earned': '100101',
'for': '111001',
'from': '0110011',
'grocery': '1010000',
'group': '1101101',
'he': '10000',
'his': '1011011',
'in': '0000',
'it': '0101100',
'later': '1001111',
'many': '1101000',
'mathematics': '0111001',
'near': '1010110',
'non-practising': '0111101',
'of': '00011',
'on': '0110111',
'parents': '1001001',
'programming.': '1010010',
'ran': '1001000',
'received': '1111010',
'small': '1001110',
'store': '0111011',
'studied': '1100100',
'supervision': '0110101',
'that': '1100011',
'the': '011000',
'this': '1100001',
'time': '1110101',
'to': '1111000',
'under': '1110111',
'was': '010001',
'where': '0111111',
'who': '0110100',
'worked': '110111',
'years': '0101111'}
The more frequent the word is, the fewer bits are required to encode the word. For example, word a was coded as 00100 (5 bits), while word RAND was coded as 0101110 (7 bits).
Reference
[1] Distributed Representations of Words and Phrases and their Compositionality, 2013.